










Ibrahim A.;1 Akintewe B.N.;2 & Akinremi O.V.3
1Adeyemi Federal University of Education, Ondo State, Nigeria
*Corresponding Author Email: ibrahima@aceondo.edu.ng …
Highlights
Abstract
Mathematics appears to be a particularly dreaded subject in our schools. The majority of individuals, regardless of age or gender, believe they have no connection with Mathematics. In some households, it is viewed as a subject meant only for those courting mental derailment. Consequently, they vow that neither they nor their descendants will ever engage with the subject. This phobia seems to have been handed down from generation to generation. Thus, the necessity has emerged to enlighten people that no one leads a life entirely devoid of Mathematics, as it is a subject applied, knowingly or unknowingly, from the womb to the tomb.
Keywords: Credit Scoring, Self-Organizing Map, Artificial Neural Network, Creditworthy, Non-Creditworthy.
1. Introduction
Credit scoring models play a pivotal role in the financial sector by distinguishing between potential good and bad loan applicants based on an evaluation of the applicants’ characteristics (Durand, 1941). Specifically defined as a statistical or quantitative tool, credit scoring aims to predict the probability of a loan applicant or existing borrower defaulting or becoming delinquent (Suleiman et al., 2012; Suleiman et al., 2017). The integration of Artificial Neural Networks (ANN), inspired by the human brain’s adaptability to new information, underscores the increasing significance of machine learning in enhancing financial services, including pre-approval processes, credit risk underwriting, investments, and various operational tasks (Tyagi, 2022).
The Multilayer Perceptron (MLP) architecture of ANN, designed for classification tasks, is particularly favored for its efficacy. It comprises an input layer, one or more hidden layers, and an output layer, each populated with numerous neurons. These neurons process incoming data and transmit an output value to subsequent layers, facilitating a dynamic analysis of credit risk (Martin and Evzen, 2006). West’s research (2000) demonstrated that within the domain of neural network techniques for credit scoring, the Radial Basis Function and Mixture-of-Experts models surpass others in performance accuracy.
This progression in credit scoring methodologies, powered by advances in artificial intelligence and machine learning, marks a transformative phase in financial analysis and decision-making. The application of such sophisticated models not only enhances the precision of credit assessments but also contributes to more informed and strategic financial planning and risk management.
The development of a credit risk assessment system leveraging multilayer neural networks has taken a significant leap forward in addressing the challenges posed by the Covid-19 pandemic. This study utilized a meticulously curated training and validation dataset comprising relevant financial information. By employing advanced algorithms such as backpropagation and the Adam optimizer, the researchers, Espinoza and Ygnacio (2024), achieved a system that demonstrates both favorable performance and satisfactory accuracy in identifying and classifying various levels of credit risk.
Additionally, the use of Multi-Layer Perceptron-Based Classification in another study focused on outlier detection within the Saudi Arabian stock market, considering variables such as inflation rate, oil price, and repo rate. Rashedi et al. (2024) showcased the MLP algorithm’s efficiency and robust performance, marking a significant advancement in financial analytics within volatile markets.
Further expanding the horizon, Provenzano et al. (2020) explored the integration of a stack of machine learning models, including natural language processing and gradient boosting machines. Their research aimed at credit rating and default prediction, highlighting exceptional out-of-sample performances. Utilizing economic sector descriptions and employing differential evolution for credit rating assignments, this study underscored the importance of advanced interpretability techniques, such as SHAP and LIME, in enhancing the transparency and understandability of machine learning models in credit risk assessment.
Chen et al. (2024) explored the influence of class imbalance on the stability of machine learning interpretations in credit scoring, using LIME and SHAP methodologies. They discovered that as class imbalance increased, the reliability of interpretations declined. Meanwhile, Kyeong and Shin (2022) tackled the challenge of balancing interpretability with performance in credit scoring models. They introduced a novel two-stage logistic regression technique based on Bayesian inference, which utilizes original features to improve default predictions while preserving model clarity. This method showed substantial advancements over traditional single-stage models. Purbayati et al. (2024) developed a logistic regression-based credit scoring model to evaluate the creditworthiness of corporate loans in banks, focusing on financial indicators. Their model achieved a 68% accuracy rate, drawing on data from 100 companies listed on the Indonesia Stock Exchange. Markov et al. (2022) conducted a systematic review of credit scoring methodologies from 2016 to 2021, examining the application of machine learning and statistical techniques across various datasets. This review offered insights into model architectures, testing methodologies, and performance evaluations, highlighting evolving best practices in the sector. AghaeiRad et al. (2017) introduced a hybrid model for credit scoring that combines the Self-Organizing Map (SOM) with a Feed Forward Neural Network (FFNN). This approach leverages unsupervised learning via SOM to enhance the FFNN’s discriminative capability, tested across four real-world datasets related to credit approval issues. By reducing data dimensionality and removing non-representative samples, SOM can significantly refine the ANN model, aligning with the primary goal of credit risk management to accurately classify creditworthy applicants. This research therefore proposes a SOM-ANN hybrid model aiming to enhance the accuracy of credit scoring classification performance. By adopting a two-stage approach that integrates Self-Organizing Maps (SOM) with Artificial Neural Networks (ANN), this study seeks to refine credit scoring categorization significantly. Distinguishing our approach from AghaeiRad et al. (2017), it’s important to note that while both Multilayer Perceptron (MLP) and Feed Forward Neural Network (FFNN) serve as neural network models employed in classification tasks such as credit scoring, they differ fundamentally in their structural design and training processes. The MLP model employs multiple layers and utilizes backpropagation for training, offering the versatility and sophisticated capability required for recognizing complex patterns. On the other hand, the FFNN model adopts a straightforward feedforward architecture that emphasizes the sequential propagation of information, without reverting. This contrast highlights our model’s potential to leverage the strengths of both architectures to achieve superior classification accuracy in credit scoring.
2. Methodology
2.1 Self-Organizing Map (SOM)
Method of SOM Model Training:
- Initiate Network weights
- Choose an input at random
- Using Euclidean Distance, pick the winning neuron:
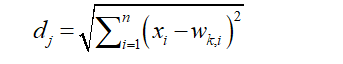
where dj is the Euclidean distance for difference between each input ( x ) and each neuron (w), = 1, …, number of neurons, and i = 1, …, number of inputs.
4. Using the weight update algorithm, update neuron weight:

5. Return to step 2 until you’ve completed your training (Suleiman et al., 2021).
2.2 Artificial Neural Networks (ANN)
In a Multilayer Perceptron (MLP) Neural Network, the architecture comprises one input layer, one or more hidden layers, and one output layer, each populated by a series of neurons. These neurons process incoming data by analyzing inputs and generating a singular output value that is relayed to subsequent neurons in the next layer. Specifically, each neuron within the input layer, identified by indices i = 1 to n, corresponds to a single predictor or attribute value derived from the input vector x. For tasks such as distinguishing between default and non-default states, the presence of a single output neuron is typically sufficient. The process utilizes an activation function, which mathematically transforms the input signal of a neuron to an output signal for further processing or for generating the final output of the network. This function is pivotal in allowing the neural network to model complex non-linear relationships between the input and output data, facilitating its ability to perform classification tasks with high levels of accuracy. Below is the activation function for the process:
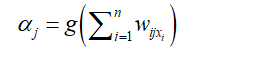
To produce the network’s output, the neurons in the output layer should function in similarity to the hidden layer’s neurons:
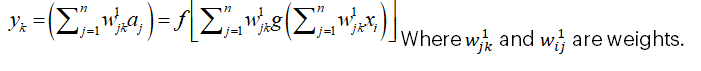
3. Illustration
The data used in this study is a secondary credit dataset of 300 cases collected from the Agricultural and Rural Development Bank of Sokoto’s credit application forms. 164 were deemed “Creditworthy,” while the remaining 136 were deemed “Non-Creditworthy”. After data preparation, the data was then used to conduct the analysis using SOM and ANN.
3.1 Self-Organizing Map (SOM)

Figure 1: SOM Network Diagram
Figure 1 indicates the SOM Network Diagram for a data dimension reduction.

Figure 2: SOM Neighbor Weight Distances
Figure 2 indicates the distances between neighboring neurons.
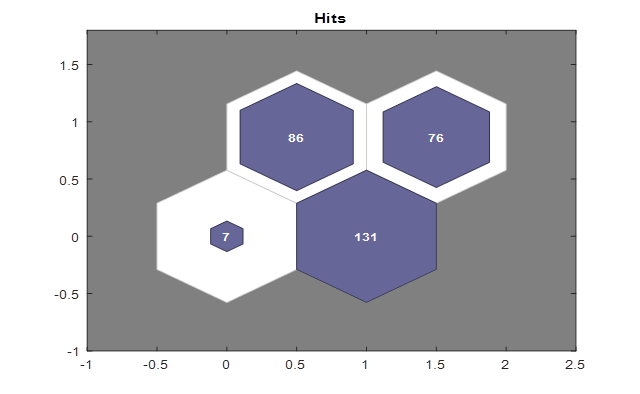
Figure 3: SOM Sample Hits
Figure 3 shows data points associated with each neuron. The data seems better if the inputs are dispersed pretty evenly throughout the neurons. The inputs are concentrated a little more in the lower-right neurons in this case. However, the data is evenly distributed.
3.2 SOM-ANN Architecture
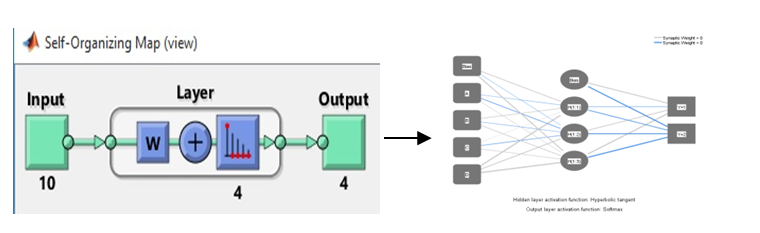
SOM ANN
Figure 4: SOM-ANN Network Diagram
Figure 4 proposed two-stage model consists of an initial Self-Organizing Map (SOM) phase followed by an Artificial Neural Network (ANN) phase. Initially, raw data features are fed into the SOM for unsupervised learning, where the SOM layer organizes neurons into clusters that reflect the underlying patterns in the data, thus forming prototypes. These prototypes, which represent the clustered data, are then used as inputs for the ANN. The ANN processes these inputs through one or more hidden layers to learn complex representations, culminating in the output layer which provides the final classification of credit risk. This sequential approach leverages the SOM’s capability to uncover complex patterns, thereby enriching the data input for the ANN. Consequently, this enhances the ANN’s classification accuracy, resulting in an improved model for credit scoring.
4. Results and Discussion
4.1 Credit Scoring Classifiers
Table 1: Credit Scoring Classifiers Performance Evaluation
| Models | Accuracy (%) | Sensitivity (%) | Specificity (%) |
| ANN | 96.3 | 95.1 | 97.8 |
| SOM-ANN | 98.6 | 97.7 | 99.4 |
Table 1 showcases the performance metrics of two models: the Artificial Neural Network (ANN) model and the combined Self-Organizing Map and Artificial Neural Network (SOM-ANN) model. The ANN model exhibits an accuracy of 96.3%, meaning it has a 96.3% probability of correctly categorizing applicants into their appropriate groups. Its sensitivity, which indicates the model’s ability to correctly identify non-creditworthy applicants, is 95.1%. Specificity, which measures the model’s accuracy in classifying good payers, is at 97.8%. This implies a 97.8% probability that the model correctly identifies applicants who are not defaulters.
On the other hand, the SOM-ANN model shows an enhanced performance with an accuracy of 98.6%, indicating a 98.6% chance of accurately classifying applicants. Its sensitivity improves to 97.7%, suggesting a higher probability of 97.7% in correctly identifying non-creditworthy applicants. The specificity of the SOM-ANN model reaches 99.4%, indicating a 99.4% probability of correctly classifying good payers, thereby significantly reducing the likelihood of misclassifying an applicant as a defaulter.
These results demonstrate that integrating SOM with ANN leads to improved classification performance, showcasing the SOM-ANN model’s superior ability to correctly identify both non-creditworthy and creditworthy applicants.
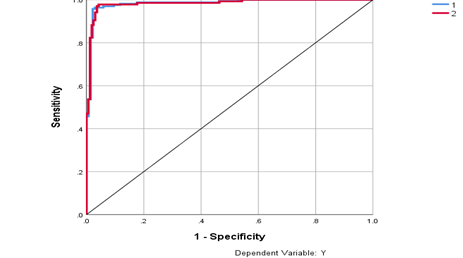
Figure 5: ANN ROC Curve
| Table 2: ANN Area Under the Curve | Area | ||
| Y | 1 | .983 | |
| 2 | .983 | ||
Figure 5 shows the trade-off between sensitivity (or TPR) and specificity (1 – FPR) of NN classifier. Since area covered under the curve is 0.98 in Table 2 and this is closer to the top-left corner of the curve indicating a better performance by the model. As a baseline, a random classifier is expected to give points lying along the diagonal (FPR = TPR). The closer the curve comes to the 45-degree diagonal of the ROC space, the less accurate the test.

Figure 6: SOM-ANN ROC Curve
| Table 3: SOM-ANN Area Under the Curve | Area | |
| Y | 1 | .993 |
| 2 | .993 | |
Figure 6 shows the trade-off between sensitivity (or TPR) and specificity (1 – FPR) of SOM-NN classifier. Since area covered under the curve is 0.99 in Table 3 and this is closer to the top-left corner of the curve indicating an improved performance by the two-stage model.

Figure 7: SOM-ANN Confusion Matrix Curve
5. Conclusion
Granting credit carries the inherent risk of default. Therefore, financial institutions play a crucial role in developing reliable credit scoring systems to evaluate the creditworthiness of loan applicants. This work introduces a hybrid method that employs both unsupervised and supervised learning techniques to ascertain whether loan applicants constitute good or bad credit risks. Specifically, our method utilizes a Self-Organizing Map (SOM), an unsupervised learning technique, to enhance the discriminatory capabilities of supervised neural networks (specifically, Multilayer Perceptron) in predicting agricultural credit defaulters among borrowers in Nigeria.
In our two-stage model, the initial phase involves clustering observations into four groups using the SOM algorithm. These clustered observations then serve as inputs for the subsequent phase, where a Multilayer Perceptron neural network is applied. The integration of SOM with Multilayer Perceptron leads to a significant improvement in classification accuracy, from 96.3% to 98.6%. Moreover, the SOM algorithm has shown to enhance the performance of the neural network in identifying non-creditworthy applicants.
Given the promising results of this study, we recommend that future research explore the combination of other classification models with the SOM algorithm to further refine and improve credit scoring methodologies.
Conflict of Interest
There is no conflict of interest during the completion of the research.
References
AghaeiRad, A., Chen, N., & Ribeiro, B. (2017). Improve credit scoring using transfer of learned knowledge from self-organizing map. Neural Computing and Applications, 28, 1329-1342.
Chen, Y., Calabrese, R., & Martin-Barragan, B. (2024). Interpretable machine learning for imbalanced credit scoring datasets. European Journal of Operational Research, 312(1), 357-372.
Durand, D. (1941). Risk elements in consumer instalments financing. National Bureau of Economic Research.
Espinoza, F.E.T., & Ygnacio, M.A.C. (2024). Development of a credit risk evaluation system using multilayer neural networks. Material Science & Engineering International Journal, 8(1), 1–7.
Kyeong, S., & Shin, J. (2022). Two-stage credit scoring using Bayesian approach. Journal of Big Data, 9(1), 106.
Markov, A., Seleznyova, Z., & Lapshin, V. (2022). Credit scoring methods: Latest trends and points to consider. The Journal of Finance and Data Science, 8, 180–201.
Martin, V., & Evzen, K. (2006). Credit scoring methods. Czech Journal of Economics and Finance, 56(3-4).
Provenzano, A. R., Trifirò, D., Datteo, A., Giada, L., Jean, N., Riciputi, A., Le Pera, G., Spadaccino, M., Massaron, L., & Nordio, C. (2020). Machine learning approach for credit scoring. arXiv preprint arXiv:2008.01687.
Purbayati, R., Muflih, M., & Pakpahan, R. (2024). Credit scoring modelling for corporate banking institutions. Journal Integration of Management Studies, 2(1), 18-28.
Rashedi, K. A., Ismail, M. T., Al Wadi, S., Serroukh, A., Alshammari, T. S., & Jaber, J. J. (2024). Multi-layer perceptron-based classification with application to outlier detection in Saudi Arabia stock returns. Journal of Risk and Financial Management, 17, 69.
Suleiman, S., Gulumbe, S.U., & Shehu, N. (2012). Default predictors in agricultural credit scoring: Evidence from Bank of Agriculture (BOA) data. In Nigerian Statistical Association (NSA) 2012 Conference Proceedings, 32-43.
Suleiman, S., Ibrahim, A., Usman, D., Yabo, B.I., & Muhammad, H.U. (2021). Improving credit scoring classification performance using self organizing map-based machine learning techniques. European Journal of Advances in Engineering and Technology, 8(10), 28-35.
Suleiman, S., M.S. Burodo, & Isah. (2017). Credit scoring using principal components analysis-based binary logistic regression. Journal of Scientific and Engineering Research, 4(12), 99-110.
Tyagi, S. (2022). Analyzing machine learning models for credit scoring with explainable AI and optimizing investment decisions. American International Journal of Business Management (AIJBM), 5(1), 5-19.
West, D. (2000). Neural network credit scoring models. Computers and Operations Research, 27, 1131-1152.
About this Article
Cite this Article
APA
Comblik K., Hawkes M., Lunel M., & Nyambayo I. (2024). Meat packaging sustainability perception among undergraduate university students studying Food and Forensic Science related courses: A Coventry University scoping exercise. SustainE. 1(2), 1-42. https://doi.org/10.55366/suse.v1i2.5
Chicago
Comblik Kinga, Hawkes Mary-Jane, Lunel Marie, & Nyambayo Isabella. “Meat packaging sustainability perception among undergraduate university students studying Food and Forensic Science related courses: A Coventry University scoping exercise.” SustainE. 1, no. 2 (February 26, 2024). 1-42. https://doi.org/10.55366/suse.v1i2.5
Received
22 November 2023
Accepted
12 February 2024
Published
26 February 2024
Corresponding Author Email: isabellanyambayo@gmail.com
Disclaimer: The opinions and statements expressed in this article are the authors’ sole responsibility and do not necessarily reflect the viewpoints of their affiliated organizations, the publisher, the hosted journal, the editors, or the reviewers. Furthermore, any product evaluated in this article or claims made by its manufacturer are not guaranteed or endorsed by the publisher.
Distributed under Creative Commons CC-BY 4.0
Share this article
Use the buttons below to share the article on desired platforms.



{kind=link}